

小売・製造、金融・公共をはじめ、幅広い業界において「先進技術を活用してビジネスモデルを変革(DX)し、お客さまへ価値提供していきたい」というテクノロジー活用への期待が高まっています。一方、その期待に反して、技術変化のスピードが速く、技術キャッチアップやその活用が難しいといった悩みもお聞きします。
そのような声にお応えするため、株式会社野村総合研究所(NRI)では「潜在的な顧客ニーズ発の技術調査」「技術動向を見据えた先進技術の早期評価」「獲得した技術の事業適用」に継続的に取り組んでいます。このような活動を通して、NRIは専門知識を用いて企業様のビジネスとテクノロジーの架け橋となり、DX実現まで伴走します。
このブログでは、NRIで推進している先進的な技術獲得の取り組みについて、ご紹介していきます。今回は、「オンプレミスでのGPUインフラの要素技術」に関する調査研究の成果をピックアップしました。
オンプレミスでのGPUインフラの要素技術
近年、生成AIの活用がますます活発化しています。これに伴い、AIモデルに対するカスタマイズ性やデータセキュリティなどのニーズが高まる中、用途や環境に応じた柔軟なAIインフラの構築が重要になっています。特に、機密性の高いデータを扱う場合や、独自のモデルを最適化したい場合には、クラウドではなく、プライベート環境でAIを稼働させる「オンプレミス」の選択肢が注目されています。
しかし、オンプレミスでAIインフラを構築するには、AI処理に適したプロセッサやネットワークなどの周辺機器、さらにはデータセンター設備まで、さまざまな要素を考慮する必要があります。
こうした要素をどのように選び、組み合わせるかが、効率的で効果的なAIインフラ実現の鍵となります。本コラムでは、AIの計算処理において重要な役割を果たすGPUを中心としたAIインフラの技術について、そのアーキテクチャや主要なコンポーネント、さらに最新の動向をわかりやすく解説していきます。
GPUの並列処理能力を最大化する技術「NVLink」と「GPU Direct」
現在、AIの処理を効率的に行うために、主にGPUが活用されています。GPU(Graphics Processing Unit)は元々画像処理を目的に作られた部品ですが、多数のコアを持つため、一度に多くの計算を並行して行う「並列処理」に優れています。この特徴が、AIの処理において非常に重要な役割を果たしています。AIの学習では、数千から数万ものパラメータを同時に調整・最適化する必要がありますが、GPUの並列処理能力を活用することで、その計算を効率化し、処理速度を大幅に向上させることを実現しています。
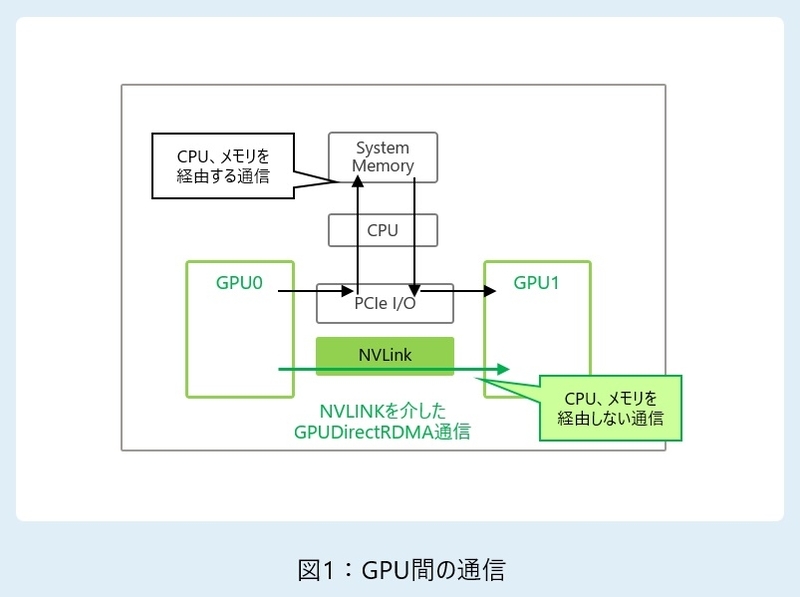
GPUの並列処理能力を活用するためには、複数のGPU間でデータを効率的に転送できることも重要になります。通常、サーバ内ではPCI Express(PCIe)を通じてGPU間の通信が行われますが、複数のGPUを使用する処理では、PCIe通信速度がボトルネックになる場面があります。
こうした課題に対応する技術として、NVIDIAが開発した「NVLink」という高速な相互接続技術があります。NVLinkは、PCIeと比べてはるかに高い帯域幅を持ち、その結果、複数のGPU間でデータをより迅速にやり取りできるようになります。この高速な通信は、大規模な並列処理やAIモデルの学習処理に大きな効果を発揮します(図1参照)。
また、「GPUDirect RDMA」という技術は、CPUやホストメモリを介さずにGPU同士が直接データをやり取りできる仕組みを提供します。これにより、通信にかかる余分な負荷を削減し、サーバ内部のGPU間通信を最適化するだけでなく、高速ネットワークを介したサーバ間の大規模分散システムにおいても、GPU間通信の高速化を実現します(図1参照)。
なお、NVLinkおよびGPUDirect RDMAはNVIDIAの独自技術であるため、導入時には注意が必要です。使用するハードウェアやOS(仮想環境を含む)に適合するドライバやソフトウェアライブラリがサポートされているかを事前に確認することが重要です。必要に応じて、利用する環境についてNVIDIAのドキュメントやサポート情報を確認しておくことをお勧めします。
GPUインフラの有効活用に欠かせない冷却機能
近年、GPUのパフォーマンスは年々向上しており、それに伴って消費電力や発熱量も増加しています。特に高密度でGPUを搭載したシステムでは、発熱量が大きいため、サーバ内部の温度が上昇しやすくなります。この過熱状態が続くと、GPUのクロック数が低下するだけでなく、動作が不安定になる可能性もあります。
こうした課題に対応するためには、効率的な冷却技術を採用することが不可欠です。特に、従来の空冷方式と比べて発熱を効率よく取り除ける「液冷技術」の導入が注目されています。液冷では冷水などの液体を用いてGPUやその他の高発熱部品から効率的に熱を取り除くことで、高い冷却能力を発揮します。その結果、これまで空冷方式では難しかった高密度でのGPU搭載が可能となり、データセンター内のスペースを効率的に活用できるようになります。
また、液冷技術の採用によって、同じ収容スペースで大幅に高い計算能力を実現できる一方で、冷却方式の変更はデータセンターの物理的設備全体にも影響を及ぼします。液冷方式を活用するには、冷却機器そのものだけではなく、液体を循環・供給するための配管や制御装置などが必要になります。さらに、液冷を採用した高密度なGPU配置では単位面積あたりの消費電力が大幅に上昇するため、データセンターの電源設備の増強や設計の見直しも求められます。こうした背景から、液冷技術の導入は、従来のハードウェア中心の取り組みだけではなく、空間・電力・冷却というデータセンター全体を俯瞰した設備設計が重要なポイントとなります。
最近では輸送用コンテナに電源や冷却設備を組み込んだ「コンテナ型データセンター」も注目されています。これにより、高発熱が予想されるシステムを効率よく稼働させながら、柔軟にデータセンターを展開できるソリューションとして期待されています。
様々なAIチップの種類と特徴
これまでにGPUを中心にAI処理に適したチップについてお話ししましたが、AIの処理にはGPU以外にもさまざまな種類のチップが活用されています。代表的なものにFPGAやASICがあり、これらはその設計や目的に応じて異なる性能や特徴を持っています。チップごとの違いを理解し、用途に応じて適切に選択することで、効率的なAIシステムの構築が可能になります。
GPU(Graphics Processing Unit)はもともとグラフィック処理に特化して作られたチップですが、高い並列処理性能を活かして、画像処理や機械学習といったAI関連の幅広い用途で活用されています。柔軟性が高いことも特徴で、現在、汎用的に使われるAIチップの代表格となっています。
一方、FPGA(Field-Programmable Gate Array)は、ハードウェアをカスタマイズできる特徴を持っています。このチップは、設計時に用途に合わせて回路の動きを変更できるため、特定のタスクに最適化を図ることが可能です。ただし、プログラムに専門的な知識が必要で、設計や設定に時間がかかることもあります。こうした柔軟性を必要とする分野で活用されています。
また、ASIC(Application-Specific Integrated Circuit)は特定の用途に特化して設計された専用チップで、AIの推論処理など特定のタスクにおいて非常に高い性能と効率性を発揮します。一般的には、すでに仕様が確定した特定用途に向けて設計されるため、GPUやFPGAに比べて汎用性は低いものの、その分だけ消費電力や処理性能面では優れた特性を持っています。
このように、それぞれのチップには異なる特徴や用途があり、AIシステムにおける最適な選択は、システムの目的や求める性能に応じて異なります。幅広い用途と柔軟性を求める場合にはGPUが、特定の用途や要件に応じたカスタマイズが必要な場合にはFPGAが、そして既に仕様が決まった特定のタスクを効率良く処理したい場合にはASICが適しています。システム設計の際には、これらの特徴をよく理解し、それぞれの強みを最大限活かすことが重要です。

オンプレミスでのGPUインフラは、AIチップの選定からデータセンターの構築・整備に至るまでを包括的に設計することが重要です。本稿では、このインフラを支える重要な技術要素の一部として、並列処理能力を高める相互接続技術や、効率的な冷却を可能にする液冷技術などを紹介しました。
NRIでは、企業のDX戦略の実現に向けて、各種技術領域における調査や検証・評価に取り組んでいます。本稿で触れた「オンプレミスでのGPUインフラの要素技術」に関する内容もその一環です。今後も、最新技術の動向をタイムリーにキャッチアップし、検証を通じて、安全性と柔軟性を両立する最適なシステムの実現に向けた支援に努めてまいります。
[関連キーワード] #GPU #オンプレミス
-

採用情報
NRIの IT基盤サービスでは、キャリア採用を実施しています。様々な職種で募集しておりますので、ご興味を持たれた方は キャリア採用ページも ぜひご覧ください。
※ 記事に記載されている商品またはサービスなどの名称は、各社の商標又は登録商標です。