

はじめに
こんにちは、NRIの矢野です。
パブリッククラウドを活用した提案や、新規構築プロジェクト、移行プロジェクトにおいて、要件定義から設計、構築、運用まで幅広く担当しています。
今回のブログでは、アマゾン ウェブ サービス(AWS)が提供するAmazon Aurora(以下Aurora)について、データベースのパフォーマンスに影響を与えずに複数のリージョンにまたがってのデータ同期、切り替えを可能とするAmazon Aurora Global Database(以下Global Database)を利用したマルチリージョン構成、そのDR(Disaster Recovery)自動切り替えについて紹介します。
こちらは、データの整合性を確保した迅速な切り替えが要件としてあり、東京リージョン/大阪リージョンを利用するマルチリージョン構成のシステムのリージョン切り替えを、RPO(Recovery Point Objective/目標復旧時点)は0秒、RTO(Recovery Time Objective/目標復旧時間)は5分を実現した事例となりますので、そのポイントについても紹介します。
なお、Global Databaseの切り替え方式については複数の種類がありますので、その違いとユースケースについても紹介します。
対象読者
- Global Databaseの利用を検討されている方、提案しようと考えている方
- Global Databaseは利用していたけど、2023/8にGAとなったマネージドフェイルオーバーはキャッチアップできていない方、これまでのフェイルオーバーとの違いやユースケースが今一つ分からなかった方
- マルチリージョン対応するかもしれない方、している方
- マルチリージョン自動切替を検討したい方、選択肢に持っておきたい方
- Global Databaseでも、Blue/Greenしたかった方
Auroraの概要
AWSでMySQL、PostgreSQLを利用している方は、Auroraを利用している方が多いのではないでしょうか。
Auroraとは
Amazon Aurora は、MySQL と PostgreSQL との完全な互換性を備えており、商用データベースの 10 分の 1 のコストで、比類のないパフォーマンスと可用性を世界規模で提供します。Aurora のスループットは MySQL の 5 倍、PostgreSQL の 3 倍です。Aurora は幅広いコンプライアンス基準とクラス最高のセキュリティ機能を備えています。Aurora は、3 つの AZ にわたってデータの耐久性を高めることで、ストレージの耐障害性を実現します (お客様は1つのコピーに対してのみ料金を支払います)。Aurora の可用性は最大 99.99% で、AWS リージョン全体にデプロイすると、お客様はグローバルデータベースを使用してローカル読み取りパフォーマンスにアクセスできます。サーバーレスでは、Aurora はほんの一瞬で数十万件のトランザクションまでスケールアップできます。
出典:https://aws.amazon.com/jp/rds/aurora/
AuroraはAWSが提供するDBaaS(Database as a Service)となります。DBaaSはマネージドデータベースとも呼ばれ、ハードウェアなどのリソース管理やパッチ適用、データのバックアップ/リージョンを跨いだデータ同期などの機能をAWSが提供してくれます。また、自動水平スケーリングをサポートする新機能となるAmazon Aurora Limitless Database*1が発表されるなど、DBaaSとしても進化を続けています。
また、AuroraではRDSでも提供されているメンテナンス(バージョンアップなど)による停止時間の極小化や、パラメータの変更を事前にGreen(ステージング)環境で確認したのちに切り替えが可能なBlue/Greenデプロイ機能*2も提供されています。本ブログ執筆時点ではGlobal Database構成とBlue/Greenデプロイ機能の併用はできないのですが、Global Database(マルチリージョン)構成で運用しつつ、バージョンアップなどのメンテナンス作業時においては停止時間を極小化するBlue/Greenデプロイを実現する方式についても紹介します。
Global Databaseの概要
まず、Global Databaseの概要についてです。AWSの公式ユーザーガイドでは次のように記載されています。
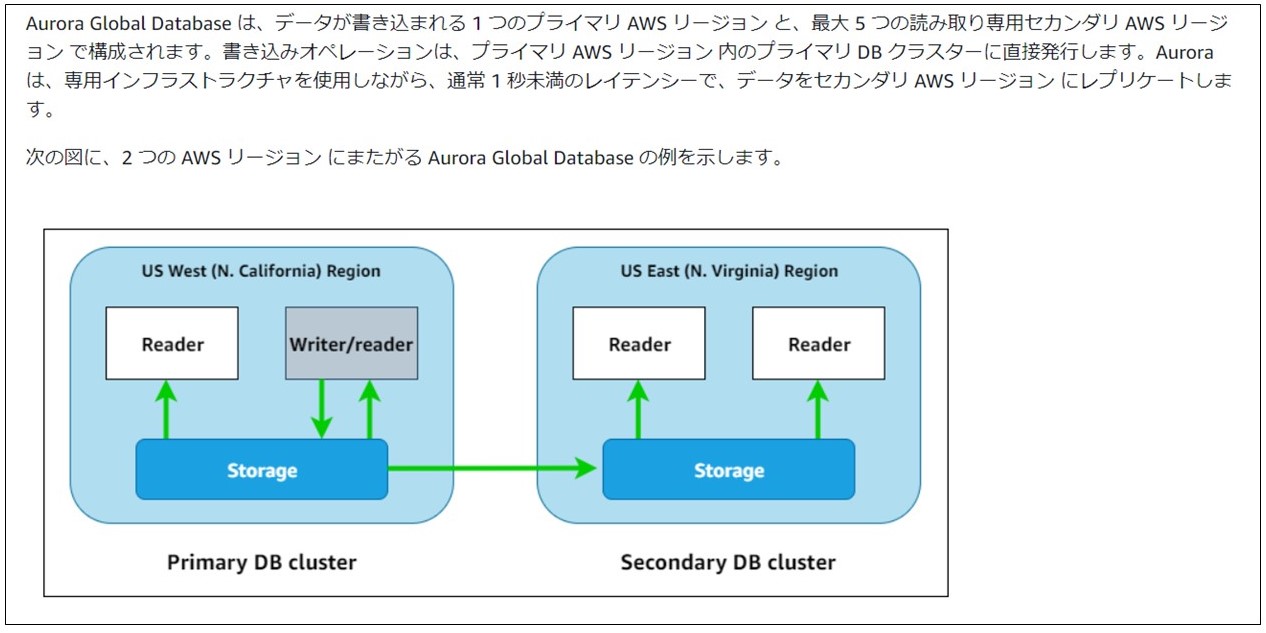
出典:https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/aurora-GlobalDatabase.html
書き込み/読み込みが可能なWriterインスタンスはプライマリクラスター側に存在し、読み込みのみ可能なReaderインスタンスはプライマリリージョン、セカンダリリージョンに配置が可能です。プライマリクラスターからセカンダリクラスターへのデータ同期はストレージレイヤーで非同期に行われるため、プライマリクラスターのパフォーマンスには影響を与えないことが特徴となります。
Global Databaseの切り替え方式
Global Databaseの切り替え方式については、大きく分けて次の2種類の切り替え方式があります。
①計画的に行うスイッチオーバー
②計画外(障害時)に行うフェールオーバー(この中でも2種類ありますので、詳細は後述します)
※②については、Global Database構成を廃止するタイミングでも利用します
ここからは、それぞれの方式について見ていきます。
①計画的に行うスイッチオーバー
・スイッチオーバーは、以前はマネージドプランニングフェールオーバーと呼ばれていた切り替え方式
・スイッチオーバーでは、Global Database構成は維持したまま、プライマリクラスターの切り替えが行われる
・また、AWS側の制御により、完全に同期した後にフェールオーバーが実施されるため、RPOは0秒となる(一方、プライマリクラスターの書き込み停止制御が入るため、プライマリクラスターへの操作が出来ないような障害時は、スイッチオーバー自体が稼働しないリスクあり)
スイッチオーバーは、正常な Global Databaseで使用するように設計されています。ユースケースとしては、定期的なDR訓練時のフェールオーバー、テストフェーズにおけるフェールオーバー、計画的なアクティブなリージョン切り替え(ローテーション)などが想定されます。また、計画的なフェールバック(切り戻し)時にも利用します。
スイッチオーバーの通常時から切り戻しまでの動作概要は次のとおりです。
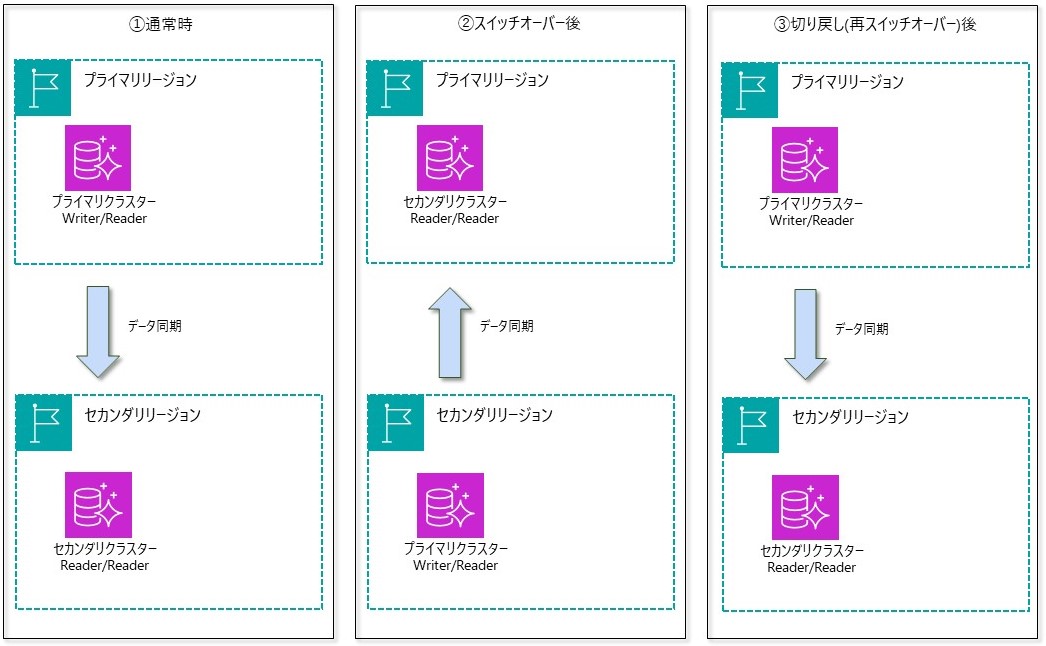
なお、スイッチオーバーでは通常時のAuroraインスタンスが維持されますので、インスタンスに紐づくPerformance Insightsも過去の情報が保持されます(後述しますが、2つのフェールオーバーのうち、手動フェールオーバーではPerformance Insightsの過去情報は元の利用しなくなるインスタンスに紐づいて保持されますので注意が必要となります)。
②計画外(障害時)に行うフェールオーバー
フェールオーバーには、次の2つの方法があります。
なお、障害時においては、フェールオーバーがAWS推奨となっています(プライマリクラスターへの書き込み停止を行うスイッチオーバーは、障害時は機能しない可能性が高いため、と考えられます)。
まずは、当初からあった手動フェールオーバーについて見ていきます。
②-1:手動フェールオーバー
・セカンダリクラスターをGlobal Database構成から削除(デタッチ)することで、スタンドアロンのプライマリクラスターに昇格させる。そのため、Global Database構成は維持されない
・Global Databaseの再構成は、手動で実施する必要がある
・もとのプライマリクラスターについても、書き込み可能な状態で残る
手動フェールオーバーの通常時から切り戻しまでの動作概要は次のとおりです。
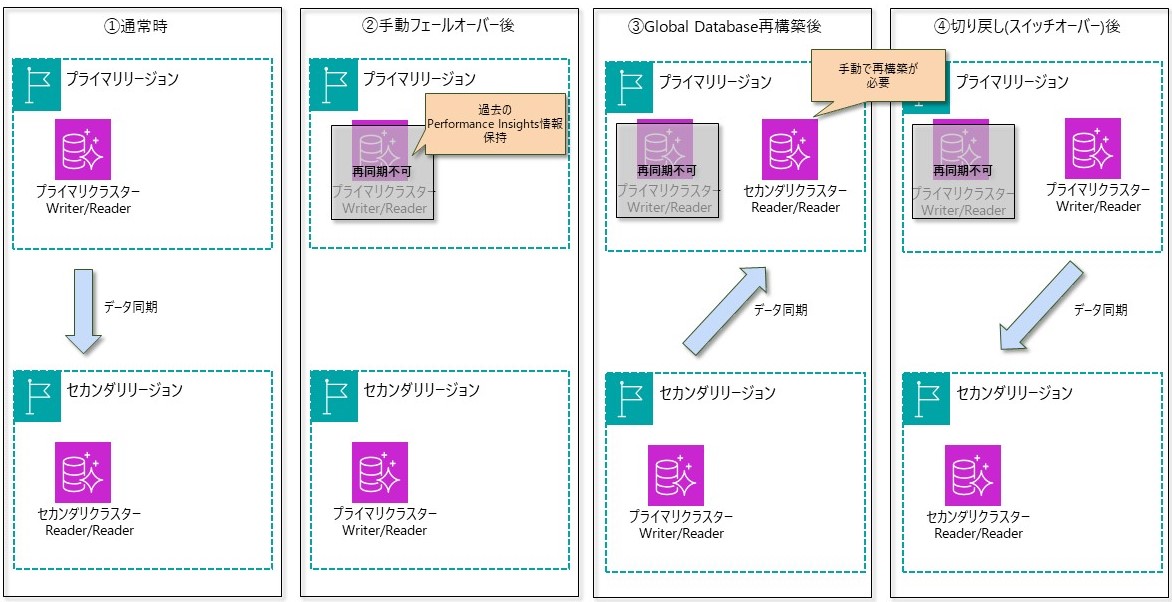
手動フェールオーバーでは、もとのAuroraインスタンスを再度Global Database構成に組み込むことはできません(Global Database構成とするためには、インスタンスやストレージから構築する必要があり、既存のインスタンスにデータを再同期するようなことはできません)。
インスタンスに紐づくPerformance Insightsの情報はもとのインスタンスが保持していますので、Performance Insightsの過去情報を残したい場合は、インスタンス自体を削除することなく残しておく必要があります(Auroraは停止しないと利用料が発生します。ただし、停止しても1週間で自動起動されるAWS仕様がありますので、インスタンスを残す場合は、Event Bridge Schedulerなどを使って定期的に停止しましょう)。
次に、マネージドフェールオーバーについて見ていきます。
もともとは手動フェールオーバーのみ実装されていましたが、2023年8月にマネージドフェールオーバーが利用可能(GA)となりました。
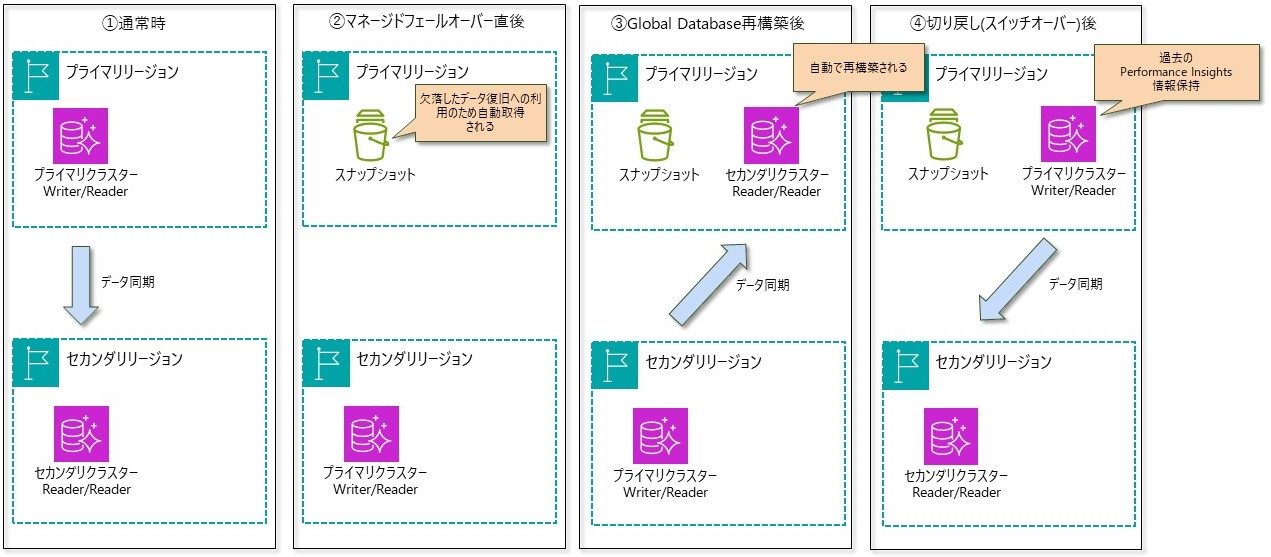
②-2:マネージドフェールオーバー
・セカンダリクラスターをGlobal Database構成から削除(デタッチ)し、スタンドアロンのプライマリクラスターに昇格させる
・元のプライマリリージョンが正常となったタイミングでセカンダリクラスター(インスタンス、ストレージ)が自動で再構築されるため、Global Database構成が維持される(過去のPerformance Insights情報を保持したクラスターが再構築される)
・セカンダリクラスターの再構築の前に、もとのプライマリクラスターのストレージボリュームのスナップショットが作成される(切り替え時に欠落したデータ復旧への利用のため)
マネージドフェールオーバーの通常時から切り戻しまでの動作概要は次のとおりです。
2025年7月追記
マネージドフェールオーバー後のGlobal Databaseの再構成については、以下の2つのパターンがあると確認できましたので追記します。 なお、利用者側でどちらのパターンを利用するか選択することはできず、AWS側でどちらのパターンで再構成するかが決定されるようです。
A:既存のインスタンスが再利用され、逆同期される。インスタンスが再利用されるため、システムスナップショット取得も行われない。データの再同期はフル同期ではなく、差分同期のため、同期にかかる転送量も少ない。
B:既存のインスタンスが再利用できない場合、新規にストレージ、インスタンスが新規構築される。
システムスナップショット取得も実施される。同期はフル同期となるため、同期にかかる転送量は大きい。
優先度は、A→Bの順であるようです。なお、②-2:マネージドフェールオーバーで記載した動作概要はBのパターンで記載したものとなります。
以下に、Aのパターンの概要図も記載します。

また、2025年7月時点で、マネージドフェールオーバーに2つのパターンがあることについてはAWSドキュメントに記載がないため、改善依頼を実施しています。
マネージドフェールオーバーが利用可能となってからは、手動フェールオーバーはGlobal Database構成を廃止したい(セカンダリクラスターやプライマリクラスターのAuroraを削除したいなど)ケースでのみ必要となるのではないかと考えられます(Global Database構成では、Auroraの停止や削除ができない仕様となっているため、Auroraの停止や削除を実施する場合は、事前に手動フェールオーバーを行うことで、スタンドアロンのクラスターとする必要があります)。
Global Databaseの切り替え方式についてまとめます。
計画外(障害時)に行うフェールオーバーはマネージドフェールオーバーを利用し、計画的に行うフェールバックなどはスイッチオーバーを利用しましょう。
・計画的に行うスイッチオーバー

・計画外(障害時)に行うフェールオーバー

・切り替え方式の比較
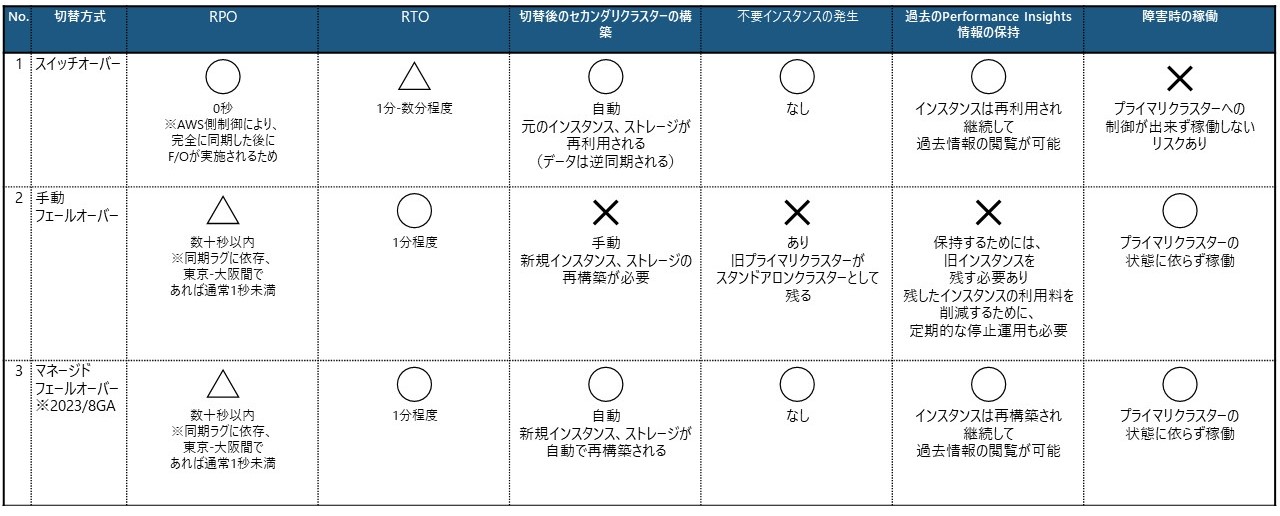
RPOの短縮
スイッチオーバーはAWS制御によりRPOは0秒が保証されますが、フェールオーバーについては、いずれの方法もRPOを短縮するために可能な限りサービス閉塞等によりプライマリクラスターへの書き込みが発生しないようにした上での実施が望まれます。
ここで、Global Databaseを利用して東京-大阪のマルチリージョン構成とし、切り替えはSaaS(Software as a Service)となるDatadogの外形監視をトリガーとする自動切り替えを実装した事例を紹介します。
こちらはRPOが0秒、RTOは5分を実現した事例となります。
・自動切り替え
この例では東京リージョンが通常利用されているリージョン、大阪リージョンが広域災害時に切り替えるDR(Disaster Recovery)リージョンです。 切り替えのトリガーは、DatadogのSyntheticsと呼ばれる外形監視サービスを利用しました。
誤発動防止(東京リージョン障害の誤検知を防ぎたい)のため、利用者の通常アクセス経路の監視のみではなく、送信元となるDatadogについては3ロケーション(バージニア、シンガポール、アイルランド)、監視対象のシステムに至る経路も3経路(CDN(Contents Delivery Network)経路、東京リージョン経路、大阪リージョン経路)とし、合計9つの外形監視がすべてNGとなった場合にのみ発動させる仕組みとしました。切り替え処理は、Datadog→Amazon Event Bridge(イベントを使用してアプリケーションコンポーネント同士を接続するサーバーレスサービス)→AWS Lambda(サーバーを管理することなくアプリケーションを構築できるコンピューティングサービス)→切り替えジョブツールの経路で実行させています。
なお、東京リージョンの異常時においても正常に処理を実行できると考えられる、大阪リージョンから切り替え処理は実行させています。
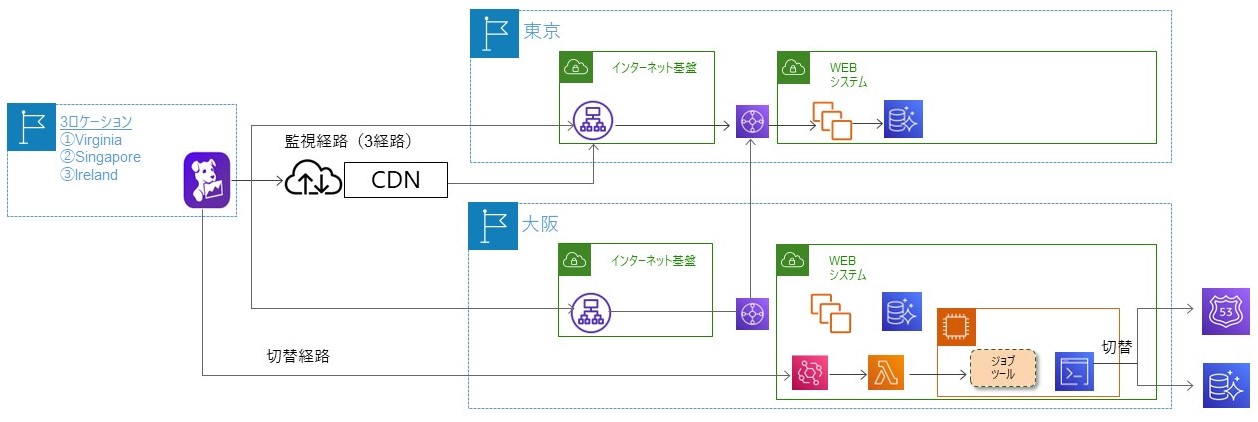
外形監視~切り替え処理開始の概要図
・RPO=0を実現するためのポイント
Global Databaseは、非同期でストレージレイヤーでのレプリケーションを行います。そのため、障害発生時のフェールオーバーでデータ消失が発生する可能性があります。なお、レプリケーションラグについては、東京-大阪間であれば通常1秒未満となります。Global Databaseを採用しながら、RPO=0を実現するためのポイントは、データベースを切り替える前に東京リージョンのWriterインスタンス(書き込み処理を実行できるインスタンス)へのトランザクションが発生しない(残らない)ようにすることです。
そのため、下記の順序でアプリケーションの経路変更や閉塞、データベースへのアクセス制御などを実施した後に、データベースの切り替えを実施します。なお、東京リージョンが障害となっている場合は切り替え等が正常に実行できない可能性があるため、一定時間経過後に処理をスキップし、後続処理を実行するようにしています。
② サービス/システム閉塞(制御不可を考慮して一定時間経過時はスキップして後続処理へ)
③ ネットワークアクセスコントロールリスト(NACL)でデータベースへの書き込みを制限(制御不可を考慮して一定時間経過時はスキップし後続処理へ)
ステートフルなセキュリティグループではなく、既存コネクションも切断するためにステートレスなネットワークアクセスコントロールリスト(NACL)での制御
④ データベースへの経路を変更(DNS切替)
⑤ Global Databaseのフェールオーバー
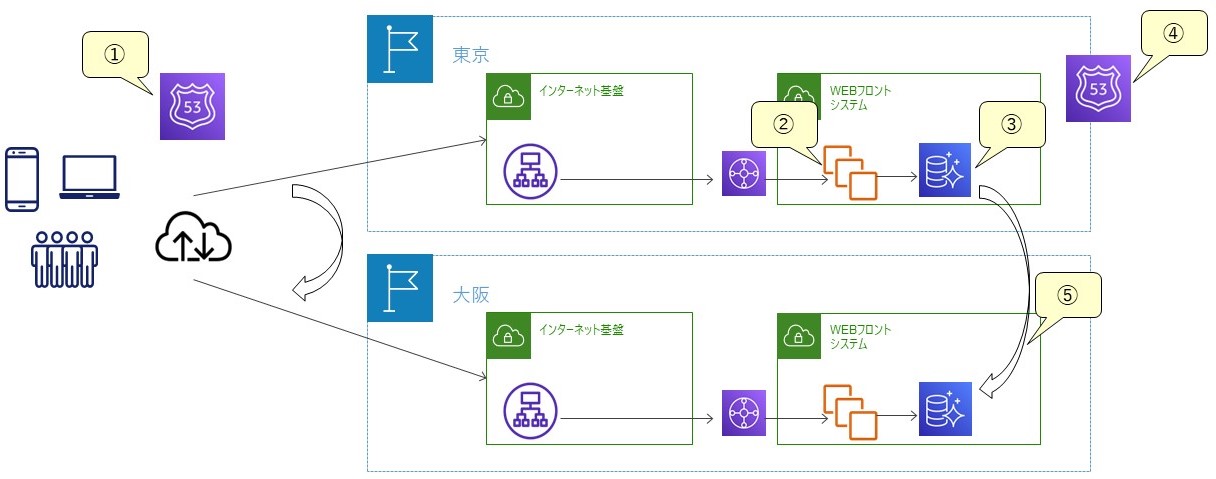
RPOゼロ秒を実現した概要図
RTOについては、各処理の実行時間やRoute53のDNS切り替え(TTL)を待った後にGlobal Databaseのフェールオーバー、大阪でのサービス閉塞解除を実施しており5分程度となります。大阪リージョンはホットスタンバイ方式(東京リージョンと同等のリソースを稼働状態で待機させておく)としており、切り替え後は大阪リージョンでサービスを継続できます。
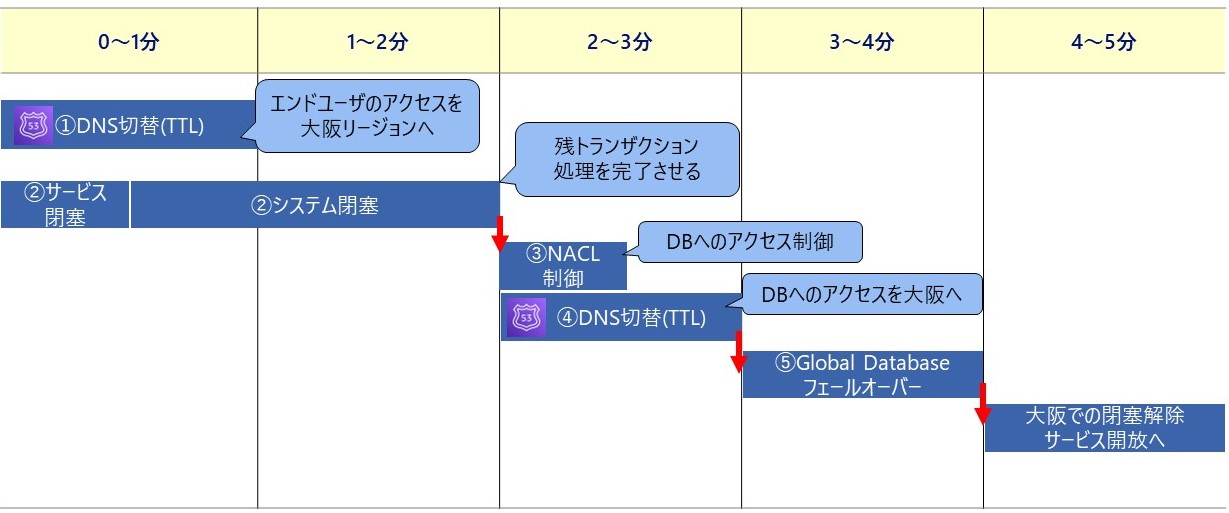
切り替えフロー
なお、切り替えは自動のみではなく、手動でも切り替え可能としています。定期的に本番環境を利用した切り替えテストも実施しており、接続先や機能追加が行われた後も切り替えが正常に行われることを確認しています。
Global Database構成とBlue/Greenデプロイ機能の併用
RDSでも提供されているメンテナンス(バージョンアップなど)による停止時間の極小化や、パラメータの変更を事前にGreen(ステージング)環境で確認したのちに切り替えが可能なBlue/Greenデプロイ機能ですが、本ブログ執筆時点では、Global Database構成では利用することができません。
ただし、通常はGlobal Database構成(Blue/Greenなし)で運用しつつ、プライマリリージョン内でのメンテナンス対応時は一時的に手動フェールオーバーによりGlobal Database構成を解除することで、Blue/Green構成に変更することができます。また、メンテナンスを実施したGreen環境への切り替え後に、再度Global Database構成とすることができます(Green環境への切り替え後は、Blue/Green構成ではなくなっているため、Global Databaseを再構築することが可能です)。
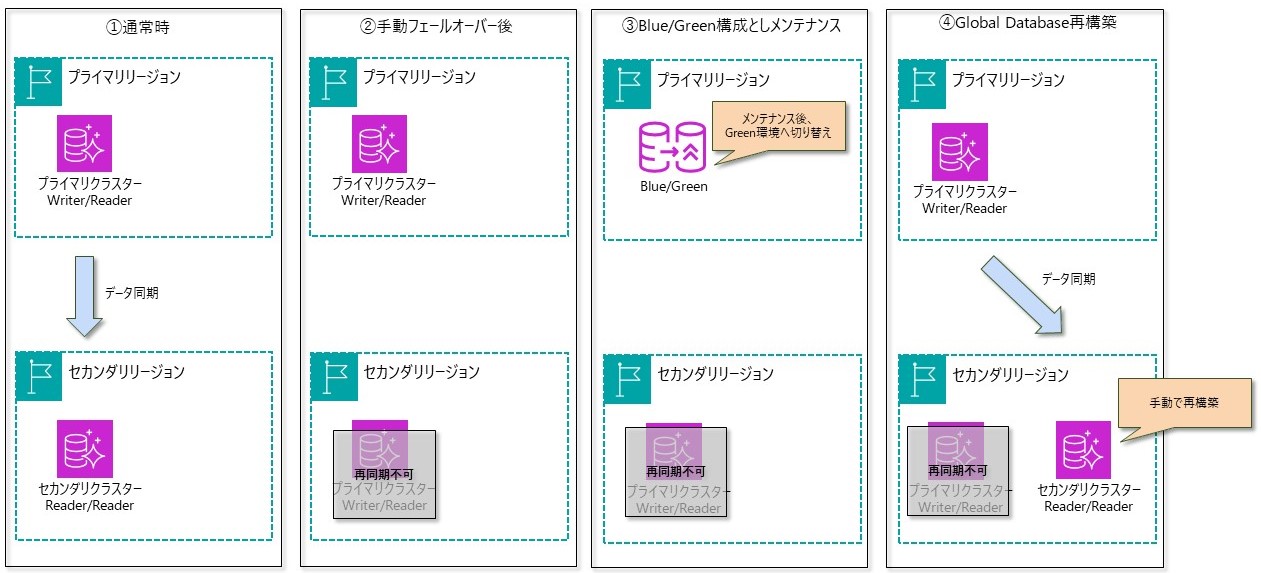 Global Database構成とBlue/Greenデプロイ機能の併用
Global Database構成とBlue/Greenデプロイ機能の併用
一時的にGlobal Database構成ではなくなりますが、Global Database構成で通常時は運用しつつ、バージョンアップなどのメンテナンス作業時はBlue/Greenデプロイ機能を利用することで、メンテナンスに伴う停止時間の短縮を実現することができます。Global Databaseの手動フェールオーバー、再構築はプライマリクラスターへの影響はありません。Blue/Green構成への変更も無影響となります。ただしGreen環境への切り替えは、1分程度のサービス断が発生します。また、Aurora PostgreSQLについては、Blue/Green構成にするためには論理レプリケーション (rds.logical_replication) が有効となっている必要があること、rds.logical_replicationなどのパラメータを有効にするには、Writerインスタンスの再起動が必要となることに注意しましょう*3。
また、Global Databaseの再構築にかかるコストについては、セカンダリクラスター構築時のストレージのフル同期の際に、プライマリリージョンからセカンダリリージョンへのデータ転送送信(OUT)料金が発生します(データ転送料金とは別に、Auroraインスタンス時間料金やストレージ料金等が各リージョンで発生します)。東京リージョンから大阪リージョンであれば、USD 0.09/GB*4となり大きなコストではありませんが、発生するコストについても確認しておきましょう。
まとめ
Global Databaseは、マルチリージョンでAuroraを構成する場合の第一選択肢となり、RTO、RPOを最も短縮できるソリューションとなります。ストレージレイヤーの同期であり、データベースのパフォーマンスへの影響も軽微となります。
フェールオーバーによる切り替え時は、マネージドフェールオーバーを利用し、RPOを短縮するために、可能な限りサービス閉塞等によりWriterインスタンスへの書き込みが発生しないようにしたうえでの実施を検討しましょう。
また、メンテナンスに伴う停止時間の短縮を図りたい場合は、一時的にGlobal Database構成を解除し、Blue/Greenデプロイ機能を利用することも可能です。
このブログが皆様のAurora、Global Database、Blue/Greenデプロイ機能の設計や運用のお役に立てれば幸いです。お困りのことなどありましたらお問い合わせ先までお気軽にご相談ください。
お問い合わせ
atlax では、ソリューション・サービス全般に関するご相談やお問い合わせを承っております。
 お問い合わせ
お問い合わせ
関連リンク・トピックス
・atlax / クラウドの取り組み / AWS(Amazon Web Services)
・2024/08/13 書籍「マルチクラウドデータベースの教科書」のご紹介 - atlax blogs
・Amazon Aurora Global Database でスイッチオーバーまたはフェイルオーバーを使用する ※外部サイトへ
・AWS Database Blog Introducing – Aurora Global Database Failover ※外部サイトへ
-

採用情報
NRIの IT基盤サービスでは、キャリア採用を実施しています。様々な職種で募集しておりますので、ご興味を持たれた方は キャリア採用ページも ぜひご覧ください。
※ 記載された会社名 および ロゴ、製品名などは、該当する各社の登録商標または商標です。
※ アマゾン ウェブ サービス、Amazon Web Services、AWS および ロゴは、米国その他の諸国における、Amazon.com, Inc.またはその関連会社の商標です。
※ Microsoft、Azure は、米国 Microsoft Corporation の米国およびその他の国における登録商標または商標です。
※ Google Cloud、Looker、BigQuery および Chromebook は、Google LLC の商標です。
※ Oracle、Java、MySQL および NetSuite は、Oracle Corporation、その子会社および関連会社の米国およびその他の国における登録商標です。NetSuite は、クラウド・コンピューティングの新時代を切り開いたクラウド・カンパニーです。