

小売・製造、金融・公共をはじめ、幅広い業界において「先進技術を活用してビジネスモデルを変革(DX)し、お客さまへ価値提供していきたい」というテクノロジー活用への期待が高まっています。一方、その期待に反して、技術変化のスピードが速く、技術キャッチアップやその活用が難しいといった悩みもお聞きします。
そのような声にお応えするため、株式会社野村総合研究所(NRI)では「潜在的な顧客ニーズ発の技術調査」「技術動向を見据えた先進技術の早期評価」「獲得した技術の事業適用」に継続的に取り組んでいます。このような活動を通して、NRIは専門知識を用いて企業様のビジネスとテクノロジーの架け橋となり、DX実現まで伴走します。
このブログでは、NRIで推進している先進的な技術獲得の取り組みについて、以下の通り複数回に分けてご紹介していきます。

今回は「本格的なマイクロサービスアーキテクチャ時代の到来に備える」「Open Application Model (OAM) を実現するCrossplane検証」「Observabilityを高める運用ツール群の技術獲得」に関する成果をピックアップしています。
1.本格的なマイクロサービスアーキテクチャ時代の到来に備える
企業活動を支えるシステムに対する要求は高まり続けています。そのような要求に応え続けた結果、システムが複雑化・巨大化し、ビジネス環境に応じてスピード感のあるシステム変更や機能拡充が難しくなるという課題を抱えることになりました(アジリティの低下)。複雑化・巨大化したシステムのアジリティを高めるには、システムアーキテクチャや技術の見直しが必要になると考えています。
アジリティを高めるためのシステムアーキテクチャの1つとして、アプリケーションを複数の独立したサービスの集合として構築する「マイクロサービスアーキテクチャ」が幅広く注目を集めています(図1)。
マイクロサービスアーキテクチャとは、システムがもつ機能を分割して1つの機能を1つのサービスで実行するよう構成し、サービス同士は厳密に定義されたAPIを介してやり取りするという構造をもつソフトウェアアーキクチャのことです。APIの仕様を変えない限り、各サービス同士は疎結合な状態を保つことができます。このアプローチをとることで、特定サービスに変更が生じた際にも他のサービスへの影響を最小化でき、個々のサービス開発が進めやすくなり、アジリティの向上につながると考えられています。
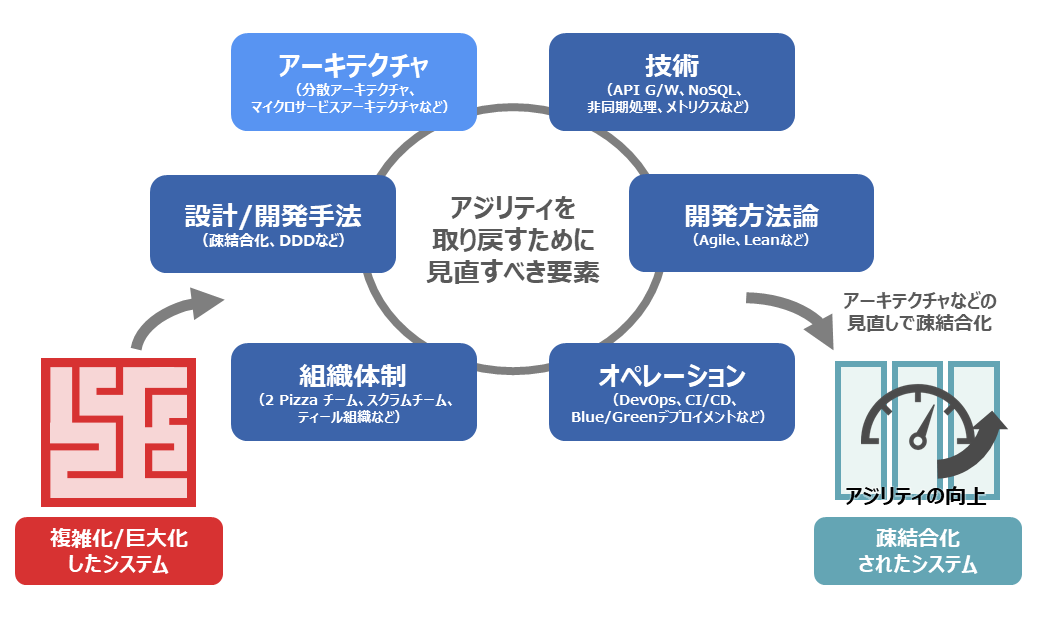
マイクロサービスアーキテクチャには、上述したアジリティ向上の他、サービスごとに柔軟にスケーリングできたり、ある機能のために開発されたサービスを、他の機能の構成要素として再利用したりとアプリケーション開発において複数のメリットがあります。ただし、マイクロサービスアーキテクチャは「銀の弾丸」ではなく、従来のモノリシックなアーキテクチャとは異なる難所もあります。例えば、多数の疎結合なサービスがバラバラに稼働することになるため、サービス間の連携や依存関係の可視化は難易度の高い設計要素の一つです。また、マイクロサービスの考え方にのっとると、サービスごとにデータベースを分けてもつことになり、単一データベースによるACIDなトランザクションモデルに任せられず、データ整合性をアプリケーション側でも考慮しなければならないケースもあります。
NRIでは、エンタープライズ企業を支える大規模なシステムを多く運用しており、それらのシステムのアジリティを高められるよう継続的な技術開発を進めています。マイクロサービスアーキテクチャに対しては、「サービス間の連携方式」「アプリケーション処理方式」「非機能要件の実現方式」「運用設計」「移行方式」について検証し、アーキテクチャパターンとして難易度の高い設計ポイントを整理しています。また、「アジリティの向上」「コストの最適化」といったシステム移行の目的に対して「評価観点」「代替策の検討」「チェックポイント」を定め、移行目的に応じてマイクロサービスアーキテクチャ採用が適切かどうかの評価を行えるようにしています。
[関連キーワード] #マイクロサービス #アジリティ
2.Open Application Model(OAM) を実現するCrossplane検証
クラウドの台頭を背景に、ロードバランサーやネットワークといったインフラのリソースはAPI経由で操作可能になり、アプリケーションと同様にコードベースでインフラ環境を管理できるようになりました。アプリケーション開発者は、コード開発の延長でインフラも含めたアプリケーション環境を構築できるようになり、アジャイル開発やDevOpsの実現に役立てられています。一方で、アプリケーション開発者は、インフラの知識が必要な範囲まで構築を担うことが増えており、そのために必要なインフラ知識の学習コストが新たな負担となっています。この問題を解決するため、MicrosoftとAlibaba Cloudは Open Application Model(OAM)というモデルを提唱しました。
OAMは、アプリケーションのソースコードやコンテナイメージ定義をインフラの管理から分離する考え方で、「アプリケーション開発者」「アプリケーションオペレーター」「インフラオペレーター」という3つの役割を定義しています(図2)。
- アプリケーション開発者
アプリケーション(コード、ランタイム、コンテナイメージ等)を構成する - アプリケーションオペレーター
トラフィックマネジメント、デプロイ方法、オートスケール設定、認証などアプリケーションの運用に必要なリソースを構成・管理する - インフラオペレーター
ネットワーク、VM、データベースなどアプリケーションが稼働するインフラを構成・管理する
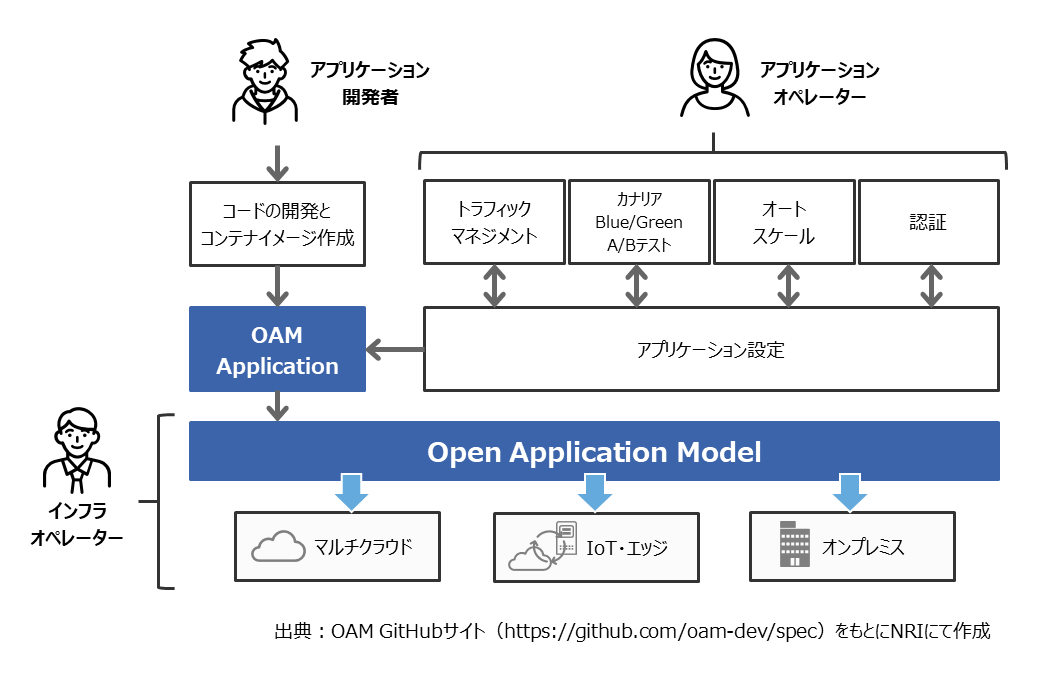
NRIでは、OAMをKubernetes上で実装したオープンソースソフトウェアの一つである「Crossplane」の調査・検証を行いました。Crossplaneによって、インフラオペレーターはクラウドプラットフォームやKubernetesクラスタ、エッジデバイスといったインフラ環境を抽象化して定義できるようになります(実体はKubernetes拡張パッケージ)。アプリケーションオペレーターは、Kubernetesの記法に従って、トラフィックマネジメント、デプロイ方法、オートスケール設定、認証などアプリケーションの運用に関わる動作を定義できます。アプリケーション開発者は、アプリケーションのロジックに関わる部分のみ記述すれば良く、インフラや運用に関わる動作設定をKubernetesの記法に従って呼び出すだけで、アプリケーションのデプロイが可能になります。インフラオペレーター・アプリケーションオペレーター・アプリケーション開発者といった役割の人が、それぞれどこまで責任を担っているのかは、Crossplane上の定義ファイルで明確にされます。そして、自分たちの責任を担う範囲に集中すれば良くなり、それ以外の部分は専門知識を持った役割の人に任せることができます。
実案件のコンテナアプリケーション構成を前提としたPoCでは、Crossplaneを用いてサンプルアプリケーションを実際に開発しました。アプリケーション開発者は自身の担当範囲を記述するだけで、インフラエンジニアが環境構築する作業を待つことなく、アプリケーションがデプロイ可能なことを確認しました。Crossplaneというツールを介して役割が明確になることで、担当者は自身が責任を持つ専門領域に注力でき、品質の向上や開発スケジュールの短縮が期待できます。
[関連キーワード] #Open Application Model(OAM) #Crossplane #Kubernetes
3.Observabilityを高める運用ツール群の技術獲得
マイクロサービスアーキテクチャは、アジリティを高め、変化への対応を容易にするアーキテクチャであり、Web企業を中心に大規模なサービスで採用されています。しかし、「1. 本格的なマイクロサービスアーキテクチャ時代の到来に備える」でも触れた通り、適用には高い設計力が必要となる部分もあり、その一つとして、システム全体の運用監視があります。どこか1つの機能でユーザーに影響ある問題が発生した場合、その発生源となったサービスを特定するためには、動的に変化する複数のサービスを横断した調査が必要となります。マイクロサービス間の通信経路や相互依存関係の追跡は、従来の監視手法とツールだけでは困難です。これを解決するには、マイクロサービス間を横断して「何が、どこで、なぜ起こっているのかを観測可能に保つ能力」が必要となります。
一般にこの能力は、"Observability(可観測性)"と言います。Observabilityを高めることができれば、問題を検出するだけでなく、複雑な依存関係を特定し、問題の根本原因にまで遡って対策を行うことができます。
Cloud Native Computing Foundation(CNCF)が公開している「Observability Whitepaper」では、Observabilityを高めるために観測すべき主要なデータとしてメトリクス、ログ、トレースを紹介しています(表1)。

観測したデータを問題調査等に活用するためには、例えば、トレースから問題の発生源となっているサービスを特定した後に、そのサービスに関連するメトリクスやログを即座に確認できるような仕組み(タグやラベルを利用したデータ間の紐づけ)が必要です。
NRIでは、高いObservabilityの実現に向けた技術調査や新たな運用プロセスの検討に取り組んでいます。例えば、Observability関連の運用ツールには、OSSやSaaS、クラウドベンダーのマネージドサービスといった様々な選択肢があります。案件の特性に応じて、多様な運用ツール群の中から最適なものを選択できるようにするため、各ツールが備える機能を調査検証し、それぞれに適合するユースケースの整理を進めています。このように、NRIではマイクロサービス時代のシステム運用を見据えて、Observabilityを高めるために必要な技術獲得に取り組んでいます。
[関連キーワード] #Observability #システム運用
-

採用情報
NRIの IT基盤サービスでは、キャリア採用を実施しています。様々な職種で募集しておりますので、ご興味を持たれた方は キャリア採用ページも ぜひご覧ください。
※ 記載された会社名 および ロゴ、製品名などは、該当する各社の登録商標または商標です。