

はじめに
こんにちは、NRIの小野です。
生成AIの業務活用が進むとともに、「Responsible AI(責任ある AI)」を実践しAIリスクに備えることは非常に重要になってきています。
Azure OpenAIサービスには、「コンテンツフィルタ」という機能があり、その中核を担います。「暴力」や「嫌悪」など有害とされる内容の入出力をブロックすることが可能なのですが、Azureポータル(Azure AI Foundry)から簡単にレベルを下げたり無効化したりと抜け道を作ることが可能です。
今回は「コンテンツフィルタを緩められないようにする」ことを目的として、Azure Policyを使って組織にフィルターのレベルを強制する方法をご紹介します。
なお、コンテンツフィルタ機能自体は以下の記事でも紹介されていますのでご参照下さい。
制御対象
コンテンツフィルタの設定画面は以下のようになっています。
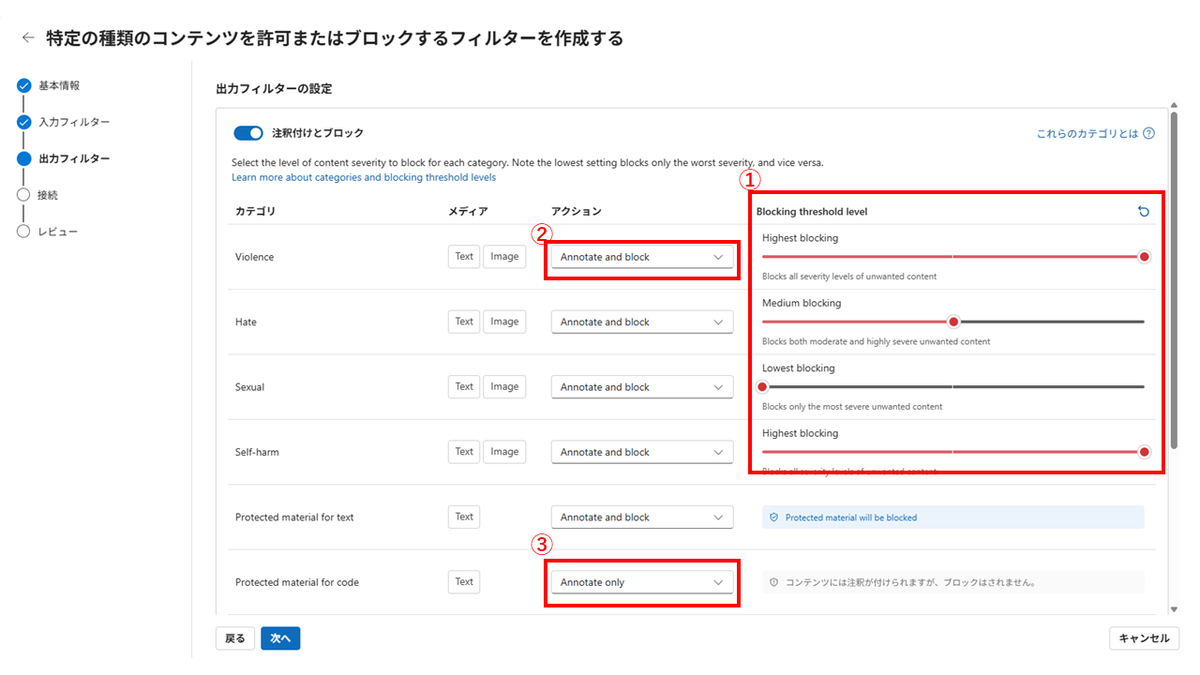
今回制御を行うのは、赤枠の「①カテゴリ別のフィルターの強度」です。「Violence/Hate/Sexual/Self-harmの4カテゴリについて、それぞれ基準以上となるフィルターを強制する」というシナリオを扱います。
類似のテーマで「②フィルターの無効化を禁止する」「③検知(Annotate)では不足なのでBlock動作を強制する」といったこともできますが、本記事のサンプルAzure Policyをちょっと改修すれば実現できますので、チャレンジしてみてください。
サンプル Azure Policy
以下の設計方針で作成したAzure Policyです。
- 4つのカテゴリそれぞれ、設定を許可するフィルターの閾値をパラメータとして入力する
- 出力結果(Completion)に対するフィルターを制御する
- 1つでも条件に当てはまらないカテゴリがあった場合は、Deny動作が行われる(デプロイに失敗する)
クリックでコードサンプル展開
{
"properties": {
"displayName": "AOAI-Completion-ContentFilterDeny",
"policyType": "Custom",
"mode": "All",
"description": "Enforce content-filter (completion) for Azure OpenAI",
"version": "1.0.0",
"parameters": {
"hate-completion": {
"type": "Array",
"defaultValue": [
"Medium",
"Low"
],
"allowedValues": [
"High",
"Medium",
"Low"
],
"metadata": {
"displayName": "allowed Hate-completion filter threshold",
"description": "'High' means less effective / 'Low' means more effective"
}
},
"sexual-completion": {
"type": "Array",
"defaultValue": [
"Medium",
"Low"
],
"allowedValues": [
"High",
"Medium",
"Low"
],
"metadata": {
"displayName": "allowed Sexual-completion filter threshold",
"description": "'High' means less effective / 'Low' means more effective"
}
},
"violence-completion": {
"type": "Array",
"defaultValue": [
"Medium",
"Low"
],
"allowedValues": [
"High",
"Medium",
"Low"
],
"metadata": {
"displayName": "allowed Violence-completion filter threshold",
"description": "'High' means less effective / 'Low' means more effective"
}
},
"selfharm-completion": {
"type": "Array",
"defaultValue": [
"Medium",
"Low"
],
"allowedValues": [
"High",
"Medium",
"Low"
],
"metadata": {
"displayName": "allowed Self-harm-completion filter threshold",
"description": "'High' means less effective / 'Low' means more effective"
}
}
},
"policyRule": {
"if": {
"allOf": [
{
"field": "type",
"equals": "Microsoft.CognitiveServices/accounts/raiPolicies"
},
{
"anyOf": [
{
"count": {
"field": "Microsoft.CognitiveServices/accounts/raiPolicies/contentFilters[*]",
"where": {
"allOf": [
{
"field": "Microsoft.CognitiveServices/accounts/raiPolicies/contentFilters[*].name",
"equals": "Hate"
},
{
"field": "Microsoft.CognitiveServices/accounts/raiPolicies/contentFilters[*].source",
"equals": "Completion"
},
{
"field": "Microsoft.CognitiveServices/accounts/raiPolicies/contentFilters[*].severityThreshold",
"NotIn": "[parameters('hate-completion')]"
}
]
}
},
"greater": 0
},
{
"count": {
"field": "Microsoft.CognitiveServices/accounts/raiPolicies/contentFilters[*]",
"where": {
"allOf": [
{
"field": "Microsoft.CognitiveServices/accounts/raiPolicies/contentFilters[*].name",
"equals": "Sexual"
},
{
"field": "Microsoft.CognitiveServices/accounts/raiPolicies/contentFilters[*].source",
"equals": "Completion"
},
{
"field": "Microsoft.CognitiveServices/accounts/raiPolicies/contentFilters[*].severityThreshold",
"NotIn": "[parameters('sexual-completion')]"
}
]
}
},
"greater": 0
},
{
"count": {
"field": "Microsoft.CognitiveServices/accounts/raiPolicies/contentFilters[*]",
"where": {
"allOf": [
{
"field": "Microsoft.CognitiveServices/accounts/raiPolicies/contentFilters[*].name",
"equals": "Violence"
},
{
"field": "Microsoft.CognitiveServices/accounts/raiPolicies/contentFilters[*].source",
"equals": "Completion"
},
{
"field": "Microsoft.CognitiveServices/accounts/raiPolicies/contentFilters[*].severityThreshold",
"NotIn": "[parameters('violence-completion')]"
}
]
}
},
"greater": 0
},
{
"count": {
"field": "Microsoft.CognitiveServices/accounts/raiPolicies/contentFilters[*]",
"where": {
"allOf": [
{
"field": "Microsoft.CognitiveServices/accounts/raiPolicies/contentFilters[*].name",
"equals": "Selfharm"
},
{
"field": "Microsoft.CognitiveServices/accounts/raiPolicies/contentFilters[*].source",
"equals": "Completion"
},
{
"field": "Microsoft.CognitiveServices/accounts/raiPolicies/contentFilters[*].severityThreshold",
"NotIn": "[parameters('selfharm-completion')]"
}
]
}
},
"greater": 0
}
]
}
]
},
"then": {
"effect": "deny"
}
}
}
}
設定してみる
Azure Policyの設定画面にて、設定・割り当てを行います。気を付けたいのが「パラメータ」の指定です。ここで、設定を許可するフィルターの“閾値”を指定しますが、コンテンツフィルタのパラメータは、
閾値Low = 強いフィルター、閾値High = 弱いフィルター
となることに注意が必要です。
フィルターの閾値が高いということは、「極端に暴力的な表現であれば、ブロックする」=「弱いフィルター」
フィルターの閾値が低いということは、「ほんの少しだけ暴力的な表現でも、ブロックする」=「強いフィルター」
という動作になります。
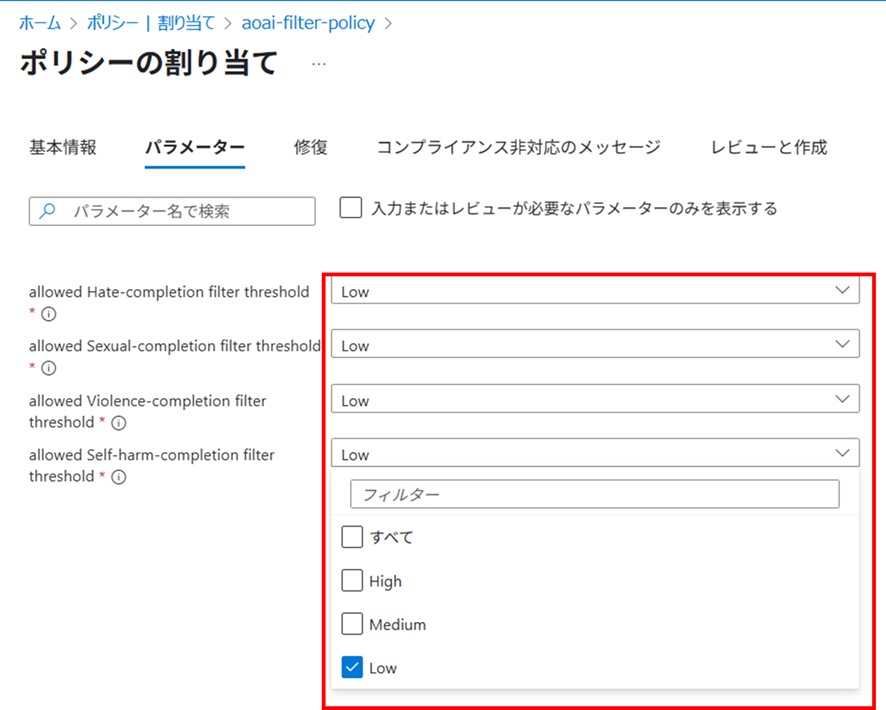
つまりこの画面例では、「どのカテゴリも強いフィルターを設定すべし」というパラメータを指定していることになります。
効果検証
それではコンテンツフィルタの設定画面を見てみましょう。
試しに「暴力的」のフィルターをMedium blocking、その他のフィルターを「Highest Blocking」に設定して、保存します。
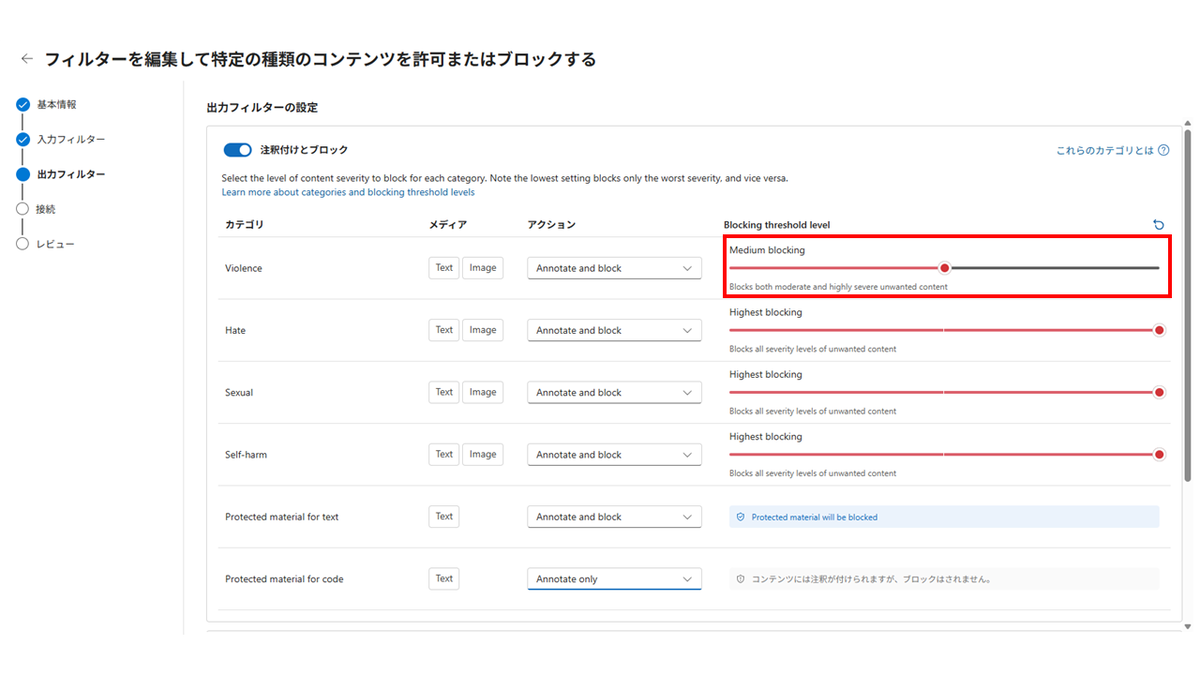
期待通り、Azure Policyによりブロックされ、デプロイに失敗しました。
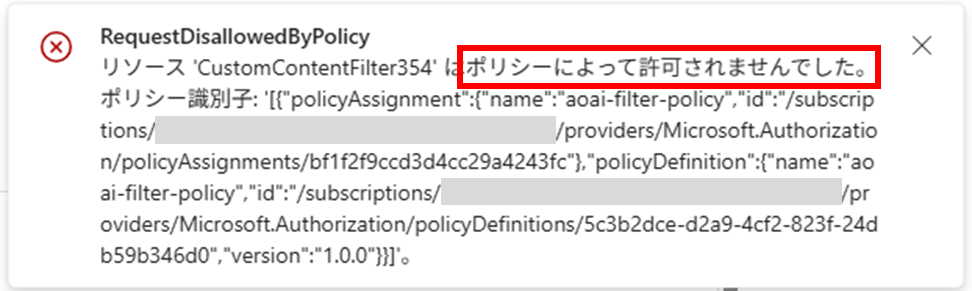
暴力的フィルターを「Highest blocking」に修正して、改めて保存すると、エラー無く進めることが出来ます。
最後に、このコンテンツフィルタを適用したAzure OpenAI Serviceと会話してみましょう。

爆弾の作り方は教えてくれず、ちゃんとフィルターの動作が確認できました。
おわりに
今回はAzureポリシーを使って「コンテンツフィルタ」の設定を強制する方法をご紹介しました。生成AIを本格活用する上では、このような統制系の機能も検討が必要になってきます。
NRIでは生成AIの業務利用に向けたPoCから、本格的な業務活用まで、さまざまな段階でご支援が可能です。お客様の生成AI活用の一助になれれば幸いです。
atlax公式SNS
各種SNSでも情報を発信しています。ぜひフォローをお願いいたします。



お問い合わせ
atlax では、ソリューション・サービス全般に関するご相談やお問い合わせを承っております。
 お問い合わせ
お問い合わせ
関連リンク・トピックス
・atlax / クラウドの取り組み / Microsoft Azure
・2025/04/03 Azureと生成AI初学者がRAG実装してみた
・2025/01/08 Azure OpenAI Serviceを活用するうえで知っておきたい有害コンテンツチェック機能のお話
-

採用情報
NRIの IT基盤サービスでは、キャリア採用を実施しています。様々な職種で募集しておりますので、ご興味を持たれた方は キャリア採用ページも ぜひご覧ください。
※ 記載された会社名 および ロゴ、製品名などは、該当する各社の登録商標または商標です。
※ アマゾン ウェブ サービス、Amazon Web Services、AWS および ロゴは、米国その他の諸国における、Amazon.com, Inc.またはその関連会社の商標です。
※ Microsoft、Azure は、米国 Microsoft Corporation の米国およびその他の国における登録商標または商標です。
※ Google Cloud、Looker、BigQuery および Chromebook は、Google LLC の商標です。
※ Oracle、Java、MySQL および NetSuite は、Oracle Corporation、その子会社および関連会社の米国およびその他の国における登録商標です。NetSuite は、クラウド・コンピューティングの新時代を切り開いたクラウド・カンパニーです。