

はじめに
こんにちは、NRIでデータ分析や機械学習技術を応用したプロジェクトを担当している徳田です。
今回のブログでは、手持ちのデータで迅速に因果効果の推定を可能にするライブラリEconMLを活用した、Double/Debiased Machine Learning(DML)による因果効果の推定についてご紹介します。
EconMLとは
EconMLは、Microsoft ResearchのALICEチームにより開発された、因果効果の推定を迅速に実施することを可能とするオープンソースのソフトウェアです。Pythonのパッケージであり、多種多様な因果効果推定のためのクラスが実装されています。EconMLのユーザ(分析者)は、自身の分析対象に合致するクラスを用いて、迅速に因果効果の推定を実施することができます。
Double Machine Learning(DML)とは
DMLとは「個体によって異なる処置効果を、共変量はすべて観測可能されているという前提の基で(共変量の影響をできるだけ取り除いて)推定する」手法です。ここで、「個体」とは、例えば、個人向けの販促施策の因果効果を考えるときは、個人のことであり、肥料が畑の収穫量に与える効果を考える時は、個々の畑(農家)であったりします。また、DMLは、共変量の数が(古典的なアプローチでは不可能なぐらい)多いケースにも適用が可能です。
DMLの手順
DMLの手順について、簡単にご説明します。
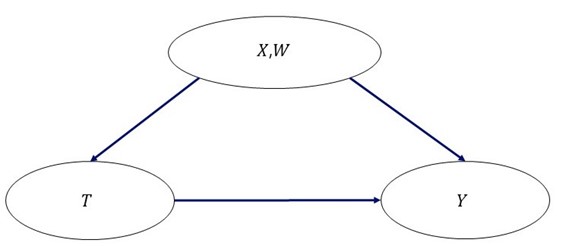
1.変数の割り当て
販促施策や肥料を撒くなどの処置を 、処置
によって変化させようとしている結果(たとえば売上や収穫量)を
とします。
またと
の両方に影響しそうな個体の属性(共変量)を
とし、おなじく個体の属性のうち、
が結果
に及ぼす影響の大きさに関係がありそうな属性を
とします。販売施策を考える際は、
としては、個人の年齢や居住地域が、また
としては個人の収入などが考えられます。
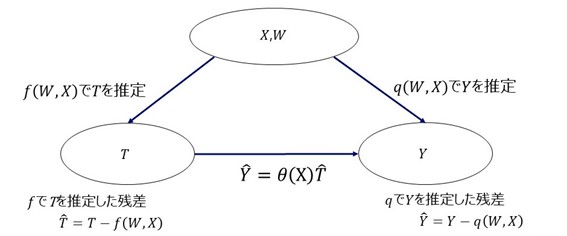
2.因果効果を推定する手順
まず、 で
の値を推定する機械学習モデル
を作成し、そのモデルによる推定値と、
との差を
とします。次に、
で
の値を推定する機械学習モデル"の"
を作成し、そのモデルによる推定値と、
との差を
とします。最後に、得られた
と
に対して、
という関数をフィットして、推定された
が
から
への因果効果であるとするのが、Double Machine Learningの手順です。
話が抽象的で解りにくいですね。大丈夫です。ここから具体的な話に入っていきます。
DMLを用いた因果効果推定の具体例1
具体的な例で、因果効果の推定方法手順についてご説明します。
新しい肥料の効果の推定
ある農村で、とある肥料の効果を推定するため、希望する農家を募って、その肥料を使ってもらうことにしました。ただ、この肥料はそれなりに値段が張るものであり、希望する農家が自身で購入する必要がありました。
秋の収穫期に、単位面積当たりの収穫量を、肥料を使用した農家と肥料を使用しなかった農家で比較してみると、10kgの差がありました。この10kgは新しい肥料の効果と言えるでしょうか?言えないですよね。
まず、肥料を購入した農家は、経済的に余裕がある農家であった可能性があり、この肥料以外にも、収穫量を上げるための投資をいろいろとできた可能性があります。また、肥料の特性として、「土壌の酸性度によってその効果が異なる」、といったことも知られており、すべての農家(畑)で土壌の酸性度は同じで、一律、単位面積あたり10kg、収穫量を上げる効果があったと考えるのは無理がありそうです。
このような状況下で、肥料が収穫量に与える効果をDMLで推定してみましょう。
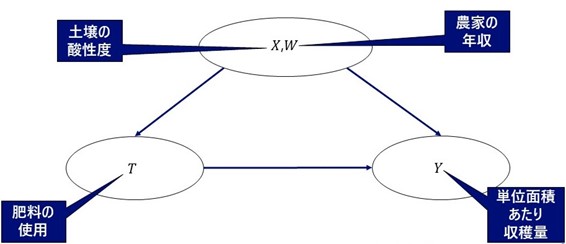
変数の割り当て
- まず、肥料を使用したか、使用しなかったかを示す変数を
(
とします。
- つぎに、
とします。
- また、同じく
とします。今回の例では、その農家が保有している畑の土壌の酸性度を
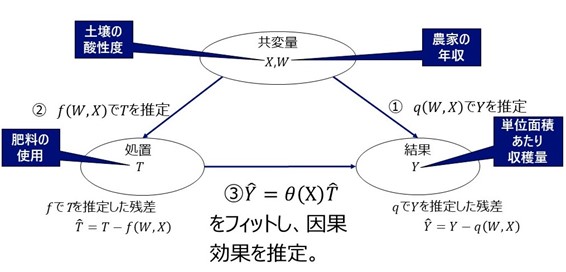
因果効果を推定する手順
- 土壌の酸性度
を作成し、
をとします。
- 土壌の酸性度
を作成し、
とします。
- 最後に、残差
と残差
の間に、
という関係があると仮定し、
を推定し、
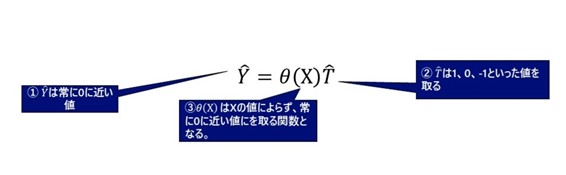
「なぜ」このような手順をとっているのか、補足させていただきます。
具体的な状況を用いた説明(肥料の使用(T)⇒収穫量(Y)の因果効果が無い場合)
まず、土壌の酸性度と農家の年収
で、単位面積あたりの収穫量
がほぼ完全に推定できてしまう状況であると仮定してみましょう。また、土壌の酸性度
と"農家" の"年収"
では、 肥料の使用の有無
はあまりうまく推定できない(言い換えると、
と
の値が似通っている農家を集めていくつかのグループを作った場合、各グループ内に肥料を使用している農家と、肥料を使用していない農家が同じぐらいの数、存在している)とします。
この状況下では、によって、
が精度良く推定できているので、
はどの農家についても(どのような
と
の組み合わせに対しても)非常に小さい値になります。
一方で、はあまり精度良く
を推定できないので、
については、頻繁に0ではない値をとります(1であったり、-1であったりします)。
この状況下でを推定すれば、これは常に0に近い値をとる関数となるしかありません。 すなわち
⇒
の因果効果は非常に小さいという推定結果となります。
は以下のグラフのようになるでしょう。

具体的な状況を用いた説明(肥料の使用⇒収穫量の因果効果がある場合)
次に、土壌の酸性度と農家の年収
だけでは単位面積あたりの収穫量
がうまく推定できない状況であると仮定してみましょう。今回も、土壌の酸性度
と"農家" の"年収"
で、 肥料の使用の有無
はあまり良く推定できない(言い換えると、 農家全体を、
と
が似たような値となっている農家をまとめて、いくつかのグループにわけた場合、それぞれのグループには、肥料を使用している農家と肥料を使用していない農家が同じぐらいの数、存在している)とします。
この時、によって、
が精度良く推定できていませんので、
がかなり大きくなっているケースがしばしば発生しています。
また、はあまり精度良く
を推定できないので、
もしばしば0ではない値をとっています。(1であったり、-1であったりします)。
この状況において、 と
にある程度の法則性があれば、
がなんらかの機械学習モデルにフィットする可能性があります。そうであれば、
を
⇒
の因果効果とみることができそうです。
と
で説明できない
が発生しており、また、
と
で説明できない
が発生しており、その二つの間に規則性があるならば、それを因果効果であると言えるのではないか、というのがDMLの考え方です。たとえば、今回の例で、土壌の酸性度がある一定の範囲にあるときに効果を発揮する肥料であったならば、DMLの結果として、次のグラフのような
が得られます。
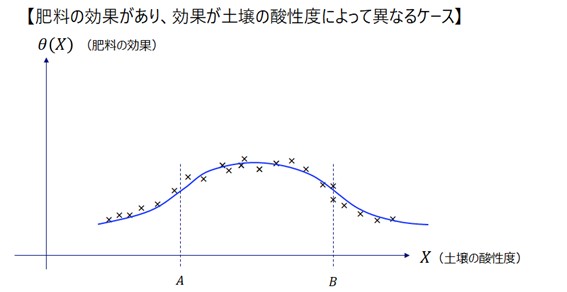
このグラフから、土壌の酸性度が一定の範囲(<
<
) の時、肥料が高い効果を発揮していることが読み取れます。
次の例は、EconMLのCase Studyで紹介されていた事例を参考に、少し単純化したシナリオです。
DMLを用いた因果効果推定の具体例2
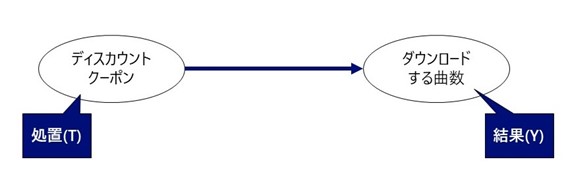
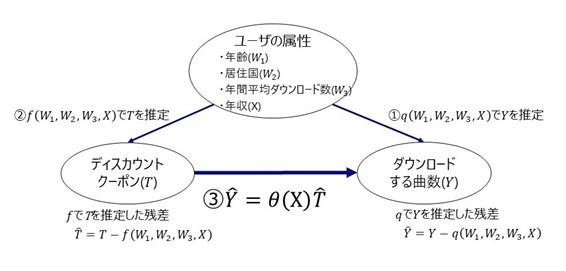
音楽配信サービスにおける販促クーポン配付
あなたは音楽配信サービスを運営している会社で販促の施策を検討しているとします。過去に何度か、ユーザにディスカウントクーポンを配付する施策を実施しており、ディスカウントクーポンを配付した週には、配布先のユーザがダウンロードした曲の数が増加していたとします。
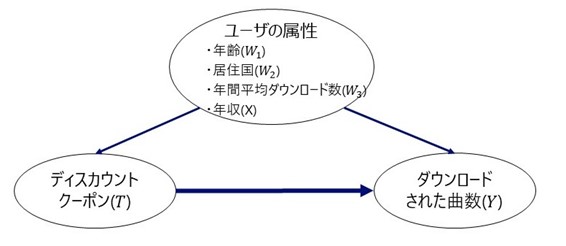
また、過去何度かディスカウントクーポンを配付した際、配付先のユーザの属性(年齢、居住国、ユーザの年間平均ダウンロード曲数、年収)には偏りがあったとします。たとえばライトユーザ向けの施策としてディスカウントクーポンを配付した場合には、ユーザの年間平均ダウンロード曲数が少ないユーザに多くのクーポンが配付されたでしょうし、特定の国のユーザに向けてクーポン配付の施策をおこなった場合には、明らかに、対象の国に居住するユーザにクーポンが配付されているはずです。
このような状況で、ディスカウントクーポン(処置)がダウンロードする曲数(結果
)に与える因果効果を推定したいとします。
変数の割り当て
- まず、ディスカウントクーポンを使用したかを示す変数を
- つぎに、
とします。
- また、同じく
因果効果を推定する手順
- ユーザの年収
、居住国
、年間平均ダウンロード数
)で、ダウンロード曲数
- ユーザの年収
をとします。
- 最後に、残差
の間に、
という関係があると仮定し、
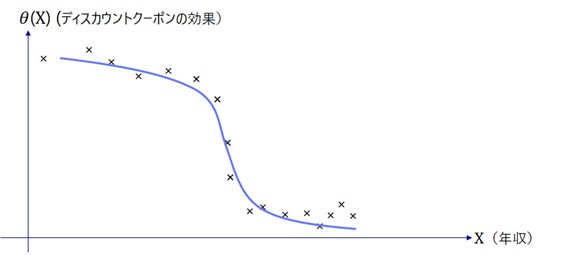
DMLの結果として、たとえば、下記のようなが得られたとします。
直感的に、ディスカウントクーポンを配付したときに、ダウンロードする曲数を増やすのは収入が少ないユーザだと思われます。みなさん、中学生だった頃を思い浮かべてください。今とは、「100円ディスカウントクーポン」の価値は違いますよね?つまり、ダウンロードする曲数は、年収の関数となっているはずです。年収をとすれば
は線形とは思えません。おそらくは年収に対して、階段状に変化すると思われます。
EconMLによるDMLの実行
Double Machine Learningを自身で実行しようとすると、から
を推定する機械学習モデル
と、
から
を推定する機械学習モデル
を生成した上で、さらにそれらモデルによる出力と
との残差を求め、最終的に、
の、
の機械学習モデルを生成する必要があります。
なかなか面倒な手順ではありますが、EconMLを用いると、簡単にDMLを実施することができます。先ほどの音楽配信サイトにおけるクーポン配付効果の例を想定したコードのイメージを以下に示します。
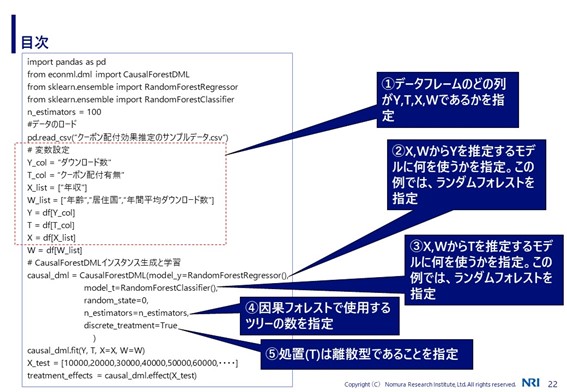
いかがでしょうか。拍子抜けするほど短いコードではなかったでしょうか?また、コードから、がじつはリストで与えられていることに気が付かれたかもしれません。実際のところ、
は複数指定することが可能です。また、処置
が離散的な変数ではないケースにも対応できます。
また、の推定に機械学習モデルを用いることで、
の数が多いケースに対応が可能です。
を推定するモデルには、ロジスティック回帰などの別のモデルを用いることも可能です。
EconMLに含まれる他のクラス
今回ご紹介したソースコード中では、 CausalForestDMLというクラスが使用されていました。これは処置の効果が、線形ではない可能性が推測されたからです。また、ここまで触れてきませんでしたが、CausalForestDMLでは、信頼区間を併せて出力することも可能です。
EconMLには、LinearDMLというクラスもあり、処置の効果が単純な線形モデルで十分と思われる場合には、こちらを使用することができます。
EconMLには実に多用なクラスが含まれており、それぞれのクラスをどのようなシチュエーションで使用するべきかを記述したフローチャートがEconMLのサイトに記載されていますので、最後に、このフローチャートをご紹介しておきます。
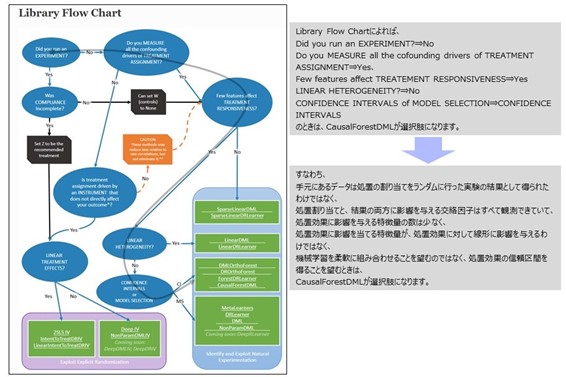
このブログが手持ちのデータに対してDouble/Debiased Machine Learningによる因果効果推定を実践しようとされる方のご参考となれば幸いです。
お問い合わせ
atlax では、ソリューション・サービス全般に関するご相談やお問い合わせを承っております。
 お問い合わせ
お問い合わせ
関連リンク・トピックス
・atlax / ソリューション / データアナリティクス - データ活用プロジェクトの立ち上げ、データ活用・管理基盤の導入、データ分析ツールの販売・サポート -
・2022/08/25 NRIの先進テクノロジーに関する取り組み ~ データを活用して 業務の最適化につなげる ~
-

採用情報
NRIの IT基盤サービスでは、キャリア採用を実施しています。様々な職種で募集しておりますので、ご興味を持たれた方は キャリア採用ページも ぜひご覧ください。
※ 記載された会社名 および ロゴ、製品名などは、該当する各社の登録商標または商標です。
※ アマゾン ウェブ サービス、Amazon Web Services、AWS および ロゴは、米国その他の諸国における、Amazon.com, Inc.またはその関連会社の商標です。
※ Microsoft、Azure は、米国 Microsoft Corporation の米国およびその他の国における登録商標または商標です。
※ Google Cloud、Looker、BigQuery および Chromebook は、Google LLC の商標です。
※ Oracle、Java、MySQL および NetSuite は、Oracle Corporation、その子会社および関連会社の米国およびその他の国における登録商標です。NetSuite は、クラウド・コンピューティングの新時代を切り開いたクラウド・カンパニーです。